Guide Orchestria
Transformation de données sans code
Orchestria est une plateforme no-code qui vous permet de créer des flux de transformation de données intelligents. Que vous travailliez avec du JSON, XML, CSV, PDF ou du texte brut, vous pouvez automatiser vos processus de transformation sans écrire une seule ligne de code. L'intelligence artificielle génère le code de transformation pour vous — vos données ne quittent jamais votre machine.
1 Créer un flow
La création d'un flow se fait en trois étapes simples. Vous définissez d'abord les formats d'entrée et de sortie, puis vous fournissez des échantillons de données, et enfin vous décrivez la transformation souhaitée.
1Choisir les formats
Sélectionnez le format de vos données d'entrée (JSON, XML, CSV, texte ou PDF) et le format souhaité en sortie. Si vous utilisez du CSV, vous pouvez préciser le séparateur et indiquer si vos données contiennent une ligne d'en-tête.
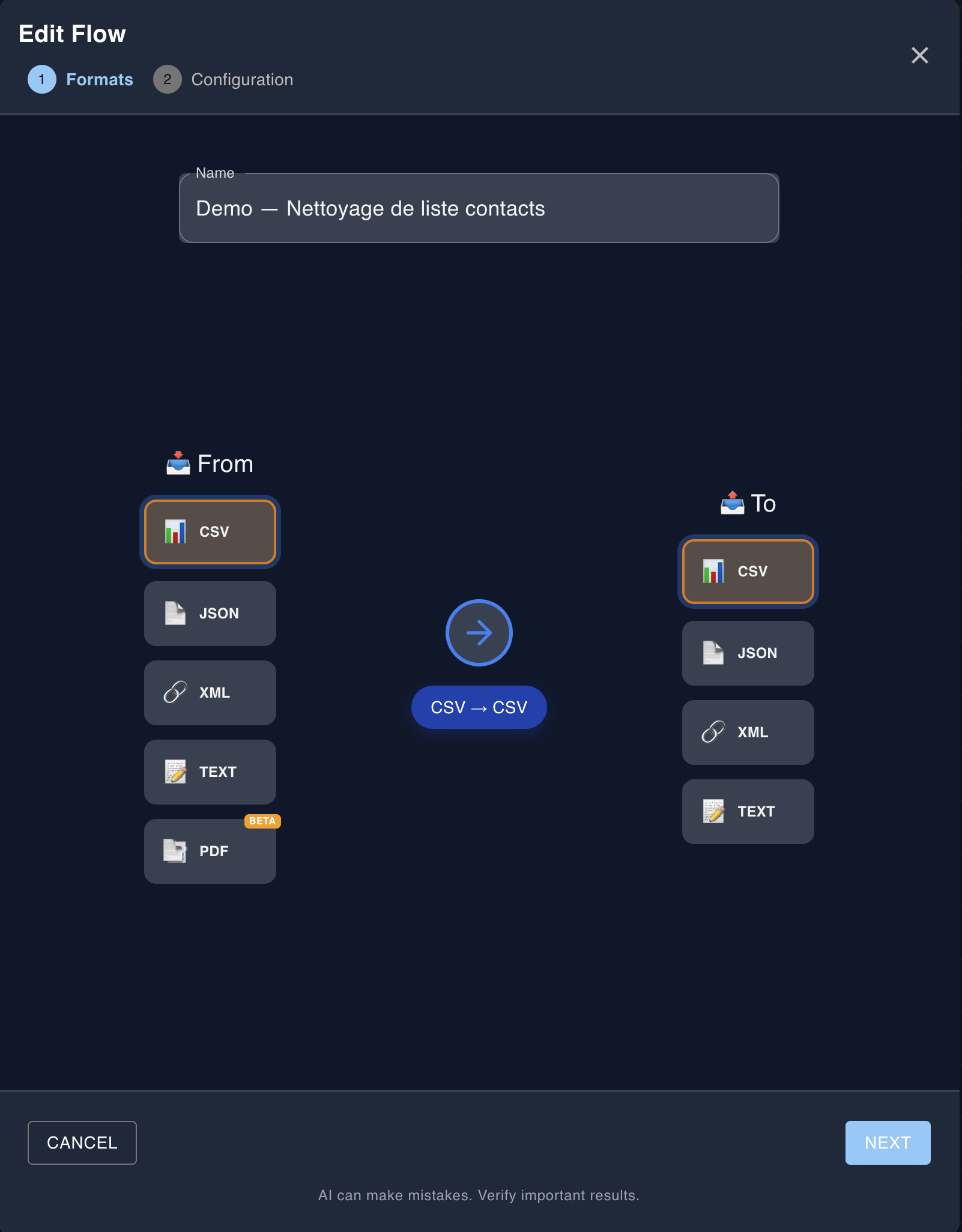
Étape 1: Choisir les formats d'entrée (JSON, XML, CSV, Text, PDF) et de sortie
2Fournir des échantillons
Copiez un échantillon réel de vos données d'entrée et montrez à quoi devrait ressembler le résultat attendu. Ces échantillons permettent à l'IA de comprendre exactement ce que vous souhaitez obtenir. Vous pouvez également importer un fichier pour générer automatiquement ces échantillons.
⚠️ Ces données seront envoyées à l'IA pour générer le code de transformation. Nous vous conseillons d'anonymiser vos échantillons.
Échantillon d'entrée:
{
"commande_id": "CMD-12345",
"date": "2025-01-15",
"montant": 150.00,
"client": {
"nom": "Dupont",
"email": "dupont@example.com"
}
}Échantillon de sortie:
{
"id": "CMD-12345",
"date_formatee": "15/01/2025",
"total_ttc": 150.00,
"client_email": "dupont@example.com"
}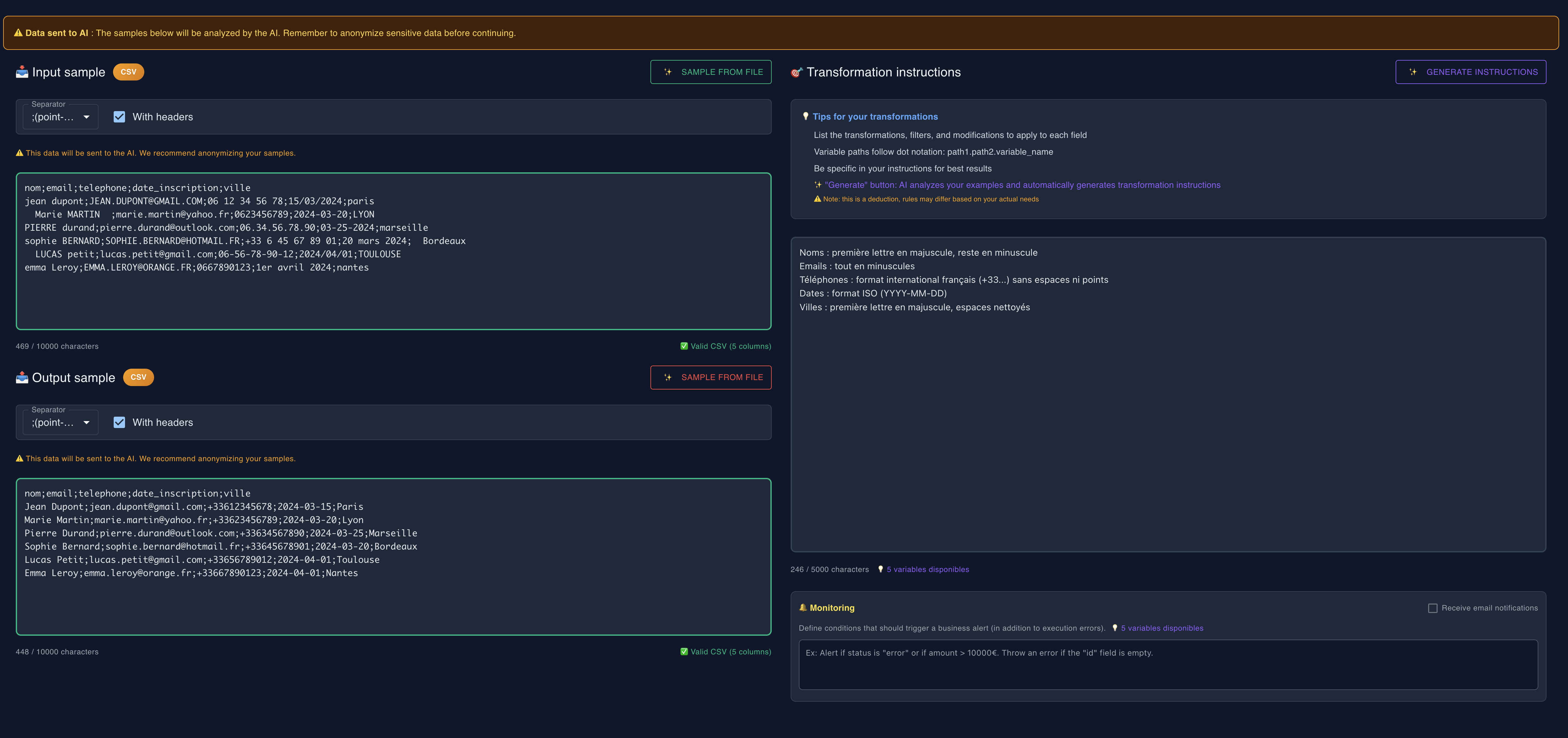
Étape 2: Fournir des échantillons et décrire la transformation souhaitée
3Décrire la transformation
Expliquez en quelques phrases ce que le flow doit faire. Par exemple : "Extraire les commandes du jour, filtrer celles dont le montant dépasse 100€, et formater la date au format français". L'IA utilisera ces instructions pour générer le code de transformation.
💡 Exemples de prompts efficaces:
- • "Extraire les commandes dont le montant dépasse 100€ et formater la date en DD/MM/YYYY"
- • "Filtrer les clients actifs, trier par date d'inscription décroissante"
- • "Ajouter un champ 'total_ttc' calculé avec TVA à 20%"
💡 Pour référencer les champs de vos données, mettez les noms de variables entre guillemets et utilisez la notation pointée pour les objets imbriqués. Par exemple : "client.adresse.ville" ou "montant_total".
Une fois ces informations fournies, cliquez sur "Enregistrer". L'IA va analyser vos échantillons et générer automatiquement le code qui réalise la transformation demandée. Pour les flows PDF, l'IA analyse le document et extrait les données dès cette étape.
2 Monitoring et Alertes
Définissez des alertes métier lors de la création du flow ou via le chat IA, et recevez des notifications automatiques.
Définir des alertes
Vous pouvez définir des alertes lors de la création du flow ou via le chat IA. Par exemple : "Ajoute une alerte si le montant dépasse 10 000€" ou "Préviens-moi si le statut est erreur".
Notifications par email
Activez l'option "Notifications email" dans les paramètres du flow pour recevoir un email à chaque alerte ou erreur.
3 Choix du fournisseur IA
Orchestria supporte plusieurs fournisseurs d'intelligence artificielle. Vous pouvez choisir celui qui correspond le mieux à vos besoins en termes de qualité et de coût.
Fournisseurs disponibles
OpenAI
Fournisseur de référence du marché. Haute précision pour la génération de flows et l'extraction PDF. Recommandé pour les cas d'usage critiques nécessitant une fiabilité maximale.
Mistral (défaut)
74% moins cher qu'OpenAI avec une qualité équivalente. Excellent rapport qualité/prix pour la majorité des cas d'usage. Supporte également l'extraction PDF.
Comment changer de fournisseur
Rendez-vous dans Mon Compte → Paramètres pour sélectionner votre fournisseur IA. Le changement s'applique immédiatement à toutes vos opérations : création de flows, modifications via le chat IA, et extraction PDF.
💡 Mistral est sélectionné par défaut pour optimiser vos coûts. Les deux fournisseurs consomment vos crédits IA de la même manière.
4 Flows PDF
Orchestria extrait automatiquement les données structurées de vos documents PDF (factures, devis, bons de commande...) grâce à l'IA Vision.
Extraction IA Vision
Chaque PDF est analysé par l'IA de vision (selon le provider configuré dans vos paramètres) qui identifie et extrait tous les champs pertinents : numéros, dates, montants, lignes de facturation, etc.
⚠️ Pourquoi valider les données extraites ?
L'IA Vision est très performante, mais pas infaillible. Une erreur d'extraction (montant mal lu, date inversée, TVA incorrecte...) peut avoir des conséquences business importantes : factures erronées, écritures comptables fausses, paiements incorrects, etc.
Les modes de validation permettent de maîtriser ce risque selon vos besoins.
Les 3 modes de validation
Lors de la création du flow PDF, vous choisissez comment les documents seront traités à l'exécution :
🚀 Mode Automatique
Le flow s'exécute immédiatement après l'extraction. Aucune vérification humaine.
→ Idéal pour les documents standardisés et fiables (même fournisseur, même format).
⚖️ Mode Contrôlé
L'IA calcule un score de confiance basé sur des règles de validation (cohérence des totaux, présence des champs obligatoires...). Si le score est supérieur au seuil (défaut 95%), le flow s'exécute automatiquement. Sinon, le PDF est mis en file d'attente pour validation manuelle.
→ Bon compromis entre automatisation et sécurité.
👁️ Mode Manuel
Chaque PDF est systématiquement mis en file d'attente pour validation humaine avant exécution.
→ Contrôle total sur chaque document.
Page de validation PDF
Accédez à la page "Validations PDF" depuis le menu pour gérer vos documents en attente :
- Aperçu du PDF et données extraites côte à côte
- Score de confiance et détail des règles de validation
- Édition du JSON extrait avant validation
- Actions en masse (valider/rejeter plusieurs PDFs)
Le JSON dans les flows PDF
À la création du flow
Quand vous créez un flow PDF, l'IA analyse votre document sample et génère automatiquement un JSON représentant la structure des données. Ce JSON devient un template (modèle) qui sera utilisé pour tous les futurs PDFs envoyés à ce flow.
Ce template définit :
- La structure des données que l'IA extraira de chaque PDF
- Les champs disponibles (numéro, date, montants, lignes...)
- Un exemple de valeurs (qui changeront à chaque document)
{
"numero_facture": "F-2024-001",
"date": "2024-01-15",
"fournisseur": "Boulanger",
"total_ttc": 219.99,
"lignes": [
{ "designation": "Produit A", "quantite": 1, "prix_ht": 183.33 }
]
}Ce que vous pouvez modifier
Le JSON généré est entièrement personnalisable :
- Renommer les champs pour correspondre à votre système
- Supprimer les champs dont vous n'avez pas besoin
- Ajouter des champs si vous savez qu'ils existent dans vos documents
- Appliquer un template prédéfini (Facture, Commande, Devis, Bon de livraison) pour démarrer avec une structure adaptée
🧪 Tester le modèle : après avoir modifié le JSON, cliquez sur "Tester le modèle" pour vérifier que l'IA remplira correctement votre structure avec les données du PDF. Ce test utilise le même prompt que l'exécution réelle.
⚠️ Attention : Gardez une structure cohérente avec vos documents. Si vous ajoutez un champ "numero_commande" mais que vos PDFs n'en contiennent pas, l'IA ne pourra pas l'extraire.
À l'exécution
Quand vous envoyez un PDF au flow, l'IA utilise le template défini à la création pour extraire les données. Elle remplit chaque champ du template avec les valeurs trouvées dans le document.
Le processus :
- L'IA lit le PDF et extrait les données
- Un score de confiance est calculé (cohérence des montants, champs présents...)
- Selon le mode de validation, le JSON est validé automatiquement ou mis en attente
- Vous pouvez corriger les erreurs d'extraction avant validation
- Une fois validé, le JSON est transformé vers le format de sortie
De l'entrée à la sortie
Le JSON extrait (input) est transformé par votre flow vers le format de sortie (output). Le prompt que vous avez écrit décrit cette transformation.
💡 Exemple : Facture PDF → JSON structuré → Format comptable pour import
🔒 Conformité RGPD
- Consentement explicite avant chaque extraction IA
- PDFs temporaires supprimés automatiquement après validation
- Expiration automatique : 7 jours maximum
Exécution des flows PDF
Une fois le flow créé, vous pouvez l'exécuter via l'interface web ou via l'API en envoyant le PDF en binaire.
Exemple d'appel API
curl -X POST https://orchestria.io/api/flows/YOUR_FLOW_UID/your-flow-name \ -H "Authorization: Bearer YOUR_API_KEY" \ -H "Content-Type: application/pdf" \ -H "X-Filename: invoice.pdf" \ --data-binary @invoice.pdf
💡 Pour les PDFs du même fournisseur, utilisez toujours le même flow pour des résultats cohérents.
5 Tester et exécuter
Une fois votre flow généré, vous accédez à une interface divisée en deux parties : à gauche l'exécution, à droite le chat avec l'agent IA.

Interface d'exécution avec formulaire d'input à gauche et résultats à droite
Exécuter le flow
Collez vos données réelles dans le champ d'entrée, vérifiez que le format correspond bien à celui configuré, puis cliquez sur "Exécuter". Le résultat s'affiche immédiatement avec le format de sortie choisi. Vous pouvez télécharger le résultat ou le copier dans votre presse-papiers.
Gestion des formats
Le résultat s'affiche dans le format de sortie configuré lors de la création du flow. Pour les webhooks asynchrones, le système retourne un identifiant d'exécution permettant de suivre le traitement dans les logs.

Résultats affichés avec le format de sortie configuré et option de téléchargement
6 Agent IA
L'agent IA vous permet d'affiner votre flow par itérations successives, directement via le chat. Vous décrivez ce que vous voulez modifier, et l'IA ajuste le code en conséquence.

Chat IA pour modifier le flow par itérations successives
Utiliser le chat
Décrivez simplement les modifications souhaitées. Par exemple : "Ajoute un filtre pour exclure les clients inactifs" ou "Change le format de la date en DD/MM/YYYY". L'IA comprend le contexte de votre flow et propose une modification adaptée. Soyez précis dans vos demandes et mentionnez les noms de champs concernés.
💡 Pour référencer les champs de vos données, mettez les noms de variables entre guillemets et utilisez la notation pointée pour les objets imbriqués. Par exemple : "client.adresse.ville" ou "montant_total".
Système de validation du code
Lorsque l'IA modifie le code de votre flow, le nouveau code est automatiquement déployé pour que vous puissiez le tester. Un bandeau de validation apparaît au-dessus du chat, bloquant temporairement les nouvelles modifications. Testez le flow avec le formulaire d'exécution à gauche, puis cliquez sur "Valider" si le résultat vous convient, ou sur "Rollback" pour revenir à la version précédente.
Rollback automatique
Si vous choisissez le rollback, le système restaure automatiquement l'ancienne version du code et la redéploie. Un message système apparaît dans le chat pour confirmer le retour en arrière. Cette fonctionnalité garantit que vous ne perdez jamais une version fonctionnelle de votre flow.
⚠️ Ce que l'agent peut faire
L'agent modifie uniquement le code métier de transformation. Il ne peut pas changer les formats d'entrée ou de sortie, ni les paramètres CSV comme les séparateurs ou la présence d'en-têtes. Pour ces modifications structurelles, vous devrez éditer les paramètres du flow ou en créer un nouveau. L'agent travaille uniquement sur la base des échantillons que vous avez fournis à la création.
7 Déployer en production
Une fois votre flow testé et validé, vous pouvez l'intégrer dans vos applications via une API REST sécurisée.
Obtenir l'URL d'exécution
Cliquez sur l'icône "œil" à côté de votre flow dans la liste pour afficher son URL d'exécution. Cette URL est unique et permanente. Vous pouvez la copier et l'utiliser dans vos applications. Les appels se font en POST avec vos données dans le corps de la requête.
Générer une clé API
Rendez-vous dans la section "API" du menu pour générer une clé d'authentification. Cette clé doit être transmise dans le header Authorization: Bearer VOTRE_CLÉ pour chaque appel. Ne partagez jamais cette clé publiquement, elle donne accès à tous vos flows.

Page de gestion des clés API pour authentifier vos appels
📘 Exemples d'appels API
curl -X POST https://orchestria.io/api/execute/YOUR_FLOW_ID \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"commande_id": "CMD-12345",
"montant": 150.00
}'import requests
url = "https://orchestria.io/api/execute/YOUR_FLOW_ID"
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
payload = {
"commande_id": "CMD-12345",
"montant": 150.00
}
response = requests.post(url, json=payload, headers=headers)
result = response.json()
print(result)const response = await fetch('https://orchestria.io/api/execute/YOUR_FLOW_ID', {
method: 'POST',
headers: {
'Authorization': 'Bearer YOUR_API_KEY',
'Content-Type': 'application/json'
},
body: JSON.stringify({
commande_id: 'CMD-12345',
montant: 150.00
})
});
const result = await response.json();
console.log(result);8 Connecteurs
Les connecteurs permettent d'automatiser entièrement vos intégrations en récupérant des données depuis des sources externes (polling) ou en envoyant vos résultats vers des services tiers (webhooks output).

Interface de configuration des connecteurs (input et output)
Connecteurs Input (Polling HTTP & SFTP)
Les connecteurs input récupèrent automatiquement des données depuis des sources externes.
Dès que de nouvelles données sont détectées, le connecteur déclenche automatiquement le flow configuré dans la page Routing. Le polling est comptabilisé dans votre quota même si aucune donnée n'est remontée, choisissez donc une fréquence adaptée à vos besoins réels.
Connecteurs Output (Webhooks & SFTP)
Les connecteurs output envoient automatiquement le résultat de vos flows vers une destination externe.
Avantage : Créez un connecteur une seule fois et réutilisez-le sur plusieurs flows (au lieu de configurer les webhooks individuellement pour chaque flow dans la page Routing).
Configuration et sécurité
Les connecteurs supportent quatre méthodes d'authentification : aucune, Bearer Token, Basic Auth, et Sign-In (pour les APIs nécessitant une connexion préalable générant un token JWT ou API key). Pour les connecteurs input, la fréquence minimale de polling dépend de votre plan (60min pour Free, 30min pour Starter, 10min pour Pro, 5min pour Enterprise). Tous les connecteurs bénéficient de logs détaillés et d'une gestion automatique des erreurs pour une fiabilité maximale.
9 Fonctionnalités avancées
Routage et chaînage de flows
Le système de routage permet d'enchaîner plusieurs flows automatiquement. Le résultat du premier flow devient l'entrée du second, et ainsi de suite. Vous recevez uniquement le résultat du premier flow en réponse, les suivants s'exécutent en arrière-plan. Pour récupérer le résultat final d'une chaîne, configurez un webhook sur le dernier flow de la séquence.

Visualisation du chaînage de flows avec diagramme interactif
💡 Exemple de cas d'usage:
Flow 1 (Extraction) → Flow 2 (Transformation) → Flow 3 (Envoi SFTP)
DNS virtuels pour environnements multiples
Les DNS virtuels vous permettent de créer des environnements de déploiement distincts (production, recette, développement) avec des URLs personnalisées. Vous pouvez ainsi tester une nouvelle version de votre flow sur une URL de test, puis basculer l'URL de production vers cette nouvelle version une fois validée. Cela permet un déploiement sans interruption de service et un rollback instantané si besoin.
Logs et diagnostic
La section "Mes Logs" centralise toutes les exécutions de vos flows. Vous pouvez filtrer par statut (succès, erreur, en cours, rejeté) et consulter les détails de chaque exécution. Les utilisateurs Pro+ bénéficient d'une analyse IA automatique des erreurs qui identifie précisément les problèmes (format incorrect, champ manquant) et propose des pistes de correction.
10 Sécurité et Confidentialité
La protection de vos données est notre priorité absolue. Orchestria est conçu pour garantir une confidentialité totale de vos données métier.
Séparation IA et données
L'intelligence artificielle est utilisée uniquement lors de la création du flow pour générer le code de transformation. Elle n'a accès qu'aux échantillons que vous fournissez, jamais à vos données réelles de production. Vos payloads d'exécution ne transitent jamais par les services d'IA.
Aucun stockage des données
Les données que vous envoyez pour exécution sont traitées en mémoire puis immédiatement supprimées. Orchestria ne conserve aucun payload, ce qui rend impossible la rejouabilité d'une exécution mais garantit une conformité RGPD totale. Seules les métadonnées (statut, horodatage, utilisateur) sont conservées pour les logs.
Protection des échantillons
Les échantillons de données que vous fournissez lors de la création d'un flow restent stockés dans votre compte de manière sécurisée et ne sont jamais partagés avec des tiers. Ces échantillons sont nécessaires au fonctionnement du flow et peuvent être modifiés en éditant le flow.
IA et documents PDF
Lors de la création ou modification d'un flow PDF, le document est transmis à l'IA pour le traitement. Seul le mode "PDF Vision" utilise l'IA pour l'extraction des données à chaque exécution. Ce mode consomme plus de ressources et doit être utilisé en connaissance de cause pour les documents complexes ou scannés.
11 Quotas
Chaque plan dispose de quotas mensuels. Voici les différents types de quotas.
Nombre de flows
Limite du nombre de flows que vous pouvez créer. Varie selon votre plan (ex: 5 flows pour Starter, illimité pour Enterprise).
Exécutions
Nombre d'appels API mensuels. Chaque appel à un flow compte comme une exécution, qu'il réussisse ou échoue.
Crédits IA
Utilisés lors de la création, modification et amélioration des flows via le chat IA. Le mode PDF Vision consomme également des crédits IA.
Consulter vos quotas
Retrouvez votre consommation dans la page "Mon compte" ou sur le tableau de bord.
12 Limites techniques
Pour garantir des performances optimales et une stabilité du service pour tous, Orchestria applique certaines limites techniques aux payloads traités.
Taille maximale des payloads
La taille maximale d'une requête (payload d'entrée) est de 10 Mo. Cette limite s'applique uniformément à tous les formats (JSON, XML, CSV, texte) et à toutes les méthodes d'exécution (API REST, webhooks, connecteurs). Au-delà de cette limite, vous recevrez une erreur 413 (Request Entity Too Large).
Capacités par format
Une limite de 10 Mo permet de traiter environ 500 000 objets JSON simples, 100 000 à 200 000 lignes CSV, ou 20 000 éléments XML complexes. Cette capacité couvre 95 à 98% des cas d'usage d'intégration standard. Pour des volumes plus importants, nous recommandons de découper vos données en plusieurs appels ou de nous contacter pour discuter d'une solution adaptée à vos besoins.